
Event driven computing is the way we build software to give you information instantly when it happens. I invented Publish/Subscribe Event driven computing at TIBCO in the 1980s.
Event driven computing and publish / subscribe (pubsub) is critical to the new world of Cloud, Mobile and now Internet of Things. I will show how publish / subscribe for IoT is very powerful way for IoT devices to interact.
First, I am going to take you on a journey of a little history to get you to the point you understand how event driven architecture led the way to the technology of today and fits into the new world of cloud, mobile, Internet of things and social. I think this has been for me as the creator of publish/subscribe an exciting journey that hasn’t ended and seems on the verge of another renaissance as we move to the Connected World of Cloud, Services, APIs, Mobile, IOT.
What is publish / subscribe, event driven computing?
The platform 2.0 era was just starting and the first distributed computer operating systems and design patterns were being created soon after I got out of college. I was thinking about the problem of migrating from the centralized world of IBM to the distributed architecture and how would users share information in such an environment:
 was becoming
was becoming 

I tell people that I had this multi-colored dream. In the spirit of Kurt Vonnegut’s Breakfast of Champions book, here is a picture in the dream I had back in 1984:

In the dream data was falling “in color” from a “data river” above into applications in real-time across a network. At the time the idea of event driven computing was radical. Virtually no VC or company saw the value of information delivered quickly to people or applications. How quaint that seems now for the IM addicted world we live in. 🙂
In publish/subscribe architecture somebody publishes some information on a topic and others who are interested in that information find about it pretty much instantly ideally at the same exact time by simply subscribing to the topic. At TIBCO we preached this philosophy of doing everything as publish/subscribe for years against the culture of the centralized batch world that existed at the time. In the batch world you ran “jobs” every week or so and processed information in large chunks. Unbelievably, almost everybody thought that batch processing weekly or monthly was great and many saw little or no value in getting information any sooner.
Event driven architecture eventually succeeded beyond all expectation. Much of the industry implemented publish/subscribe on top of point to point using the hub and spoke Message broker pattern. If you don’t want to understand the underlying technology of event driven computing and publish / subscribe you can skip the next few sections and get directly to the new stuff about new platforms and IoT.
Google Example of polling disadvantages compared to event driven publish/subscribe
I think a good way to understand this is to see how Google worked in the day. In IPv4 internet there are roughly 2 billion addresses. Google literally tries every single possible IP address. If an answer comes back from that address Google walks the website and indexes the information so you could then find that website content in searches. The process of scanning every possible IP address took about 6 months back in the early days of the internet. I’m not joking. If you put up a new web site it could take months before Google would recognize that you were there. This is the opposite of publish/subscribe. (:))
Believe it or not in the early days of the internet that wasn’t such a big issue. Web sites were pretty static. Also, if information changed 2 or 3 times between the time they scan you they won’t know. Google demonstrates the advantages and problems with polling very well. Incidentally, here is what Google says today:
“There is No set time in for Google to initially index your site – the time taken can vary. The time it does take may vary based upon factors such as; * Popularity of the site (Whether it has any links to it) * Whether the content is Crawl-able (Server Responses and Content type) * Site structure (how pages interlink) It is possible for a site to be crawled/indexed within 4 days to 4 weeks. In some cases, it may take longer.”
Wow! Of course this not only applies to the first time they index you but also they make no promises how frequently they will come back and look for new content.
Let’s consider a different way to do Google with Publish/subscribe
What if every website published the information when they changed using publish/subscribe. Google or anybody interested in knowing about changes would get this information instantly. This would mean when you did a search all the information would be current to the latest event. Google does a good job of hiding the fact that much of their information is old.

There are lots of ways to leverage publish / subscribe in the internet but this was never implemented. Wouldn’t this be cool if we could do this? I won’t mislead you, this is a hard thing and TIBCO did work with Cisco to make publish / subscribe part of standard router protocols but it was a weak form that wouldn’t give you what I described above.
a) website content would be delivered to interested parties instantly (including Google)
b) instead of missing key content parties would be notified of all changes
c) information could be classified according to a naming scheme such that you could get real-time updates on almost any information from stock prices to weather, traffic,voting results, sports results etc… simply by subscribing to that topic.
d) numerous intermediary services might have been created already that leveraged the information published to the cloud using this new way of providing information and services
Such a world doesn’t exist because publish/subscribe was never implemented in the cloud or internet. Google does all the work of collecting all the information so we are left with waiting until Google or some other service creates an API to get at the information.
However, we finally have the world of APIs being created. 10s of thousands of services are being created each year by thousands of companies. Check out my blog on cool APIs. The event driven cloud is being created every day with these new services.
What is the excitement over Pubsub about?

“Pubsub” was used almost universally by financial firms. It was shocking to look out over a trading floor of thousands of traders and realize the software I wrote with my colleagues was underpinning the entire financial system of the world. Pubsub was also used by many other companies in other industries. An entire industry of middleware with companies such as IBM creating IBM MQ, Websphere in reaction to our success with messaging as the paradigm for the event driven distributed architecture.
I frequently found people excited about the pubsub idea. Speaking at college campuses, to different companies and colleagues at different companies there are a number of people that get very excited about pubsub. Why was pubsub so popular?
“Agile Architecture”
 becomes this
becomes this 
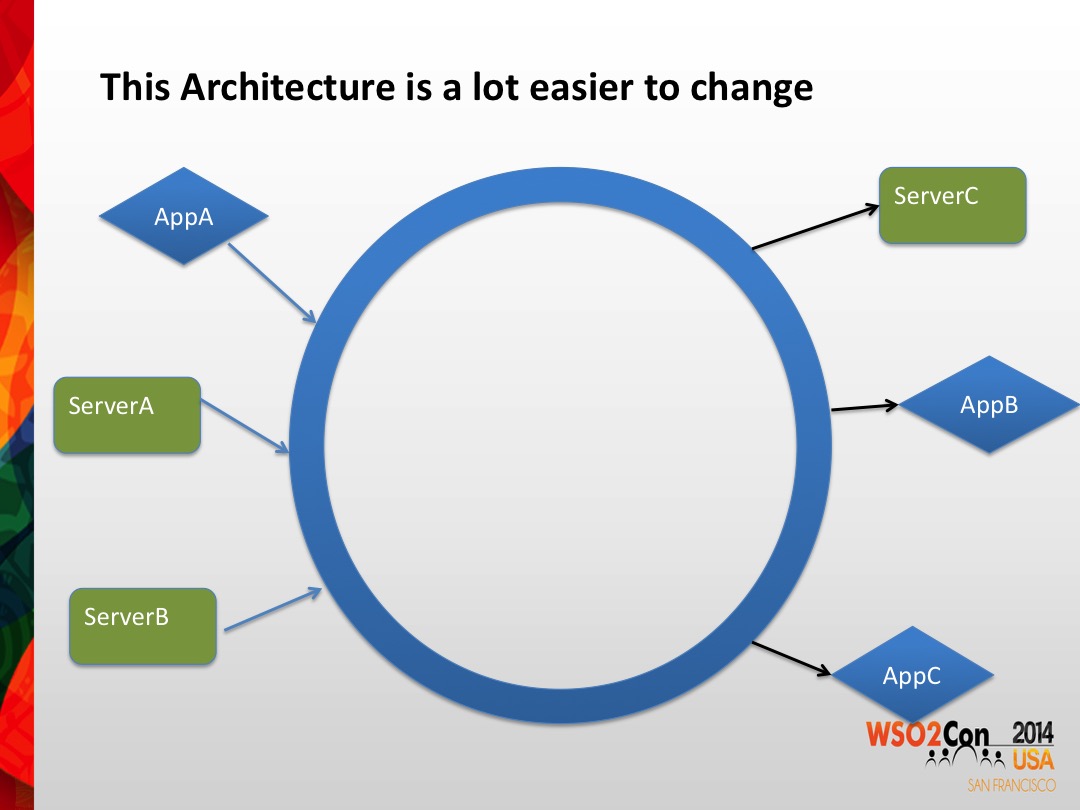 becomes this
becomes this When you designed software back in the days it was a pretty much a “waterfall approach”. You could draw boxes and lines and show how everything connected as in the above left diagram. As Enterprise Architecture got more and more complicated many enterprises looked like the left diagram above. Since communication code is amongst the hardest code to write and everything was point to point any change was a big hassle. More importantly, software became extremely brittle. The slightest change required lots of changes in unrelated software and lots of testing to see if you didn’t break something.
One company I worked at called this list of things that they needed to do as the “pile.” What they observed was it took longer and longer to remove items from the pile and the pile was growing larger and larger. One aspect of agility is to be able to make changes without this brittleness and fast enough the pile doesn’t grow for long. Publish/subscribe and messaging reduces the pile by removing all the point to point connections with a single connection to a message bus that can be configured to decide what messages should go from anyplace to anyplace else.
Sometimes when I talk to engineers I realize they never got this architectural lesson. Many engineers still think that pubsub gets in the way of writing code to go from point A to point B. Point to point seems the most efficient code possible. Engineers still aren’t taught frequently how to gain maximum agility in the code they write by leveraging the event driven messaging patterns. They are not taught the pitfalls of writing tightly bound code like on the left. Another way to say it is that it gives lots of job stability to write code like on the left diagram. 🙂
“Simplified communication”
Pubsub simplified the whole communications paradigm dramatically. Now, all you did was design independent pieces that didn’t care about the places it connected to. I simply subscribed or published the relevant subjects and everything to do with delivery of the data to whoever was interested was handled by the “network messaging services.” This makes building component architecture much simpler. I didn’t even need to know the “URL” of the service. I left the data formatting and distribution decisions to separate easily configured services, like message brokers and mediation service buses.
The asynchronous nature of pubsub led to highly efficient and scalable applications. Pubsub was the node.js of platform 2.0 world. 🙂
Pubsub is turning into the defacto way IoT works for partly this reason. A need for simplified communication that is robust and flexible because we don’t know how all the devices will need to talk to each other. Pubsub just simplifies all of the interconnection, makes it easy to add and delete devices which makes IoT easier and more fun.
“Late binding”
Pubsub implied late binding. Late binding is a very powerful concept in software. I didn’t need to know much about a service to use it. I could change the service easily and add things. I could add new services, break services apart and easily “mediate” how everything used everything else. In the financial world this meant I could add new data services trivially. I could delete them as easily. I could decide I wanted to handle orders one way one month and the next month decide to use a different clearing house the next.
In the IoT world “late binding” means being able to add new devices or remove them easily without having to reconfigure the world or change anything. No hiccups. Devices can change, upgrade, be multiplied or disappear and the system dynamically adjusts.
“Easy Reuse”
I could add services dynamically and they were discovered. I could add value easily to a service through another service. I mentioned earlier the idea of “Business Activity Monitor” and calculation engine. It was easy to take data that was being published and mine it for more information, produce something else that was useful. For instance something as simple as taking the bid and ask price and producing an average. I could take a basket of stocks and compute an arbitrage or a new risk assesment tool and add it to the mix easily. The ease of doing this is empowering and created agility.
In the IoT world being able to reuse devices for numerous functions will be the key to the “Network Effect” I talk about.
“Discovery”
Pubsub usually is designed to leverage pubsub to announce services so it makes discovery of services easy. This makes network architecture easier. I can take down and bring up new components and the system automatically adjusts and notices the new services or the lacking of other services. Everything becomes an event and I can automate the activity to the event rather than the old way of having to manually configure files, command line scripts, restart applications and all the hullabaloo that came with point to point, configured, locked in approaches to communication. Turning change into an “event” meant that things could adjust automatically whereas no event means that a human must act as the event and go around and do changes, reboot things whatever. Automatic, event driven pubsub is easier, more natural and less error prone.
Three Patterns to Publish / Subscribe Event Driven Architecture
Broadcast Pattern
In a publish/subscribe broadcast architecture information is sent once to all parties and they decide if it is of interest and throw it away if it isn’t. If they can be very efficient about throwing away unneeded information then this scheme works well. We were able to get the overhead to throw away messages so good at TIBCO that only 1% or less of the computers time was spent throwing away messages leaving 99% of the computer free to process the messages it considered more interesting. Also, sending a message via broadcast frequently consumes no more bandwidth in the network than sending it to all the computers since for many network schemes the bandwidth is shared among a number of devices.
The protocol that underlies networking in corporations is called IP and it has always supported a type of communication called UDP which allows you to send information to all computers attached to the network simultaneously. This protocol is at a hardware level analogous to the idea of publish/subscribe.
At first blush this may seem wasteful to have every computer get every piece of information but consider that the information only needs to be sent once and everyone gets it. If a piece of information is useful to only one subscriber this might be wasteful to send it to everyone but the we found ways to make this work really efficiently. This implementation of publish/subscribe allowed TIBCO in 3 years to get 50% market share in financial trading floors.
Polling Pattern

The parties can all contact you periodically to ask if you have anything of interest to them. Your subscribers might contact you hundreds of times and you have nothing new for them. That’s wasteful. If I have 2 updates in rapid succession some may miss some information.

Hub and Spoke (Broker) Pattern – The current best practices approach
The broker performs the work of delivering information to all the interested parties. It handles security, reliability, transactional semantics simplifying the task for each client. The broker has to copy N times to each of N interested parties. Some latency is introduced but modern message brokers are extremely efficient. The broker pattern requires that you know the broker exists and establish connection to it. Otherwise semantically it is equivalent to the broadcast pattern.
Overall
At this point you should be seeing that broadcast pattern has numerous advantages over the hub and spoke or polling pattern. I publish once and thousands of parties could get it instantly. In the hub and spoke model some subscribers at the end of the queue are going to be pissed they get information much later than others. If polling is used some of the subscribers may miss information entirely. If they want a fast response they can poll more frequently but this will place a large burden on the servers. I will still get the information later than with hub and spoke or publish/subscribe.
The efficiency of publish/subscribe broadcast model
We demonstrated the incredible efficiency of publish/subscribe with a cool demo. We wrote a program which simulated balls bouncing around a room.
You could start with one ball and increase the number. Imagine each ball is its own IoT. As the balls bounced the way they communicated was to send their position to a central server which computed their next position and sent them this information. The central computer handled the bouncing trajectories and the physics. In the hub and spoke or polling model the latencies and work required of the central server increases dramatically and as the square of the number of balls. Even if you optimize this and figure out a linear algorithm the cost on the network bandwidth grows very fast. With a larger number of balls the performance of a hub and spoke where each ball has to be informed from a central point becomes extremely poor very fast making the demo look bad.

If the information between the balls is sent using publish / subscribe each ball sends only one message. Here I am. The other balls get all the messages of the other balls and compute on their own because they have all the information they need. The result was the balls move smoothly even as you scale the number of balls up dramatically. This very visually and dramatically gets the point of publish/subscribe very well. It convinced a lot of people why our publish/subscribe was so much better at information distribution.
Publish/subscribe over broadcast worked really well on trading floors of financial firms and many other places where timeliness was king.
Problems with publish/subscribe over broadcast
You can skip this section if you don’t want to get too technically deep.
There are many interesting problems we solved in broadcast publish/subscribe. You may find these enlightening. If not, just skip it.
1) UDP isn’t reliable. One problem with the internet broadcast protocol is that it is not reliable. A message is sent to all computers on the network but the computers have the right to drop it if they are busy. A trader doesn’t want to miss information. The only way around this initially was to wait until the endpoint noticed it missed a message. It would sit there and go: “Wait, I got message 97 and then 99. What happened to 98? Send me 98 again.” Our protocol understood this and promptly sent message 98 to the affronted party. However, in the meantime a lot of time could have elapsed and they now have information much later than others. If you are trying to win that 1/4 of a point better price that’s a problem. Also, this turns out to have an even more serious problem because when someone misses a message they send a message to ask for a resend. The server then has to do a lot of additional work to satisfy this party that missed the message. Maybe 3 or 4 out of thousands miss the message so instead of sending the message only once I actually in reality have to send it 4 or 5 times. Now imagine that I am getting loaded down and the message traffic is high and more computers are dropping messages so now lots more are asking for repeats. This happens precisely when the network is busy so that it exacerbates the problem. These were the first examples of network storms. It happened and we found ways around it.
I later invented and patented the idea of publishing the message more than once. This may seem wasteful at first. However, the probability of dropping 2 messages by the same subscriber is a lot lower than dropping a single message. Therefore if 3 or 4 needed rebroadcasts if I send the message twice there is a good chance these 3 or 4 will get the second message and there will be vastly less situations where I need to retransmit the message to specific parties. For the reliability protocol it means instead of dealing with 3 or 4 failures there are no failures. My cost for doing that is simply to send the message twice which is a lot less than sending it 5 times which I ended up doing by optimistically assuming everyone will get the first message. Not only that but the guys who missed the first message are a lot happier because they got the second message which came only a millisecond late so for all intents and purposes they didn’t see nearly as large a latency problem. Let’s say I am sending these messages not over local network but these messages are going out over multiple connected networks to get to its destination. Along the way the message may have had to be retransmitted several times. These errors in networks happen and the latency introduced when an error occurs is substantial. If I send the message twice one of the messages may not need a retransmission so it gets there much faster than the other message. So, even in a case where you use an underlying reliable protocol sending a message more than once can result in superior performance. This fact is important in any scenario where timeliness is important and depending on the fanout of the messages it can be more efficient for the network. Exercise left for the reader.
2) UDP doesn’t scale beyond local networks easily. Broadcast protocol is great if the total world is a few hundred or thousand computers but when you connect networks of computers many of which are unlikely to be interested in information from the other networks then the efficiency of broadcast publish/subscribe loses out. We tried to get internet providers to support UDP over wide area networks but they didn’t want to do that. We invented a protocol called PGM which was implemented in most Cisco routers that allowed broadcast over wide area networks efficiently but it was never used widely.
So we developed the idea of a publish/subscribe proxy/router. The proxy sat between 2 networks and helped manage load. If everyone on a certain network had no interest in a particular subject then there is no point in broadcasting that information to that network. This required knowing what people on this new network were interested so we developed the idea that when you subscribed to something it was sent out as a broadcast message. A proxy could listen to this and make a note. “Hey, somebody is interested in messages like this on this network” The proxy knowing this subscription information could then decide if it was useful to pass the information on to their network or not. A hardware company called Solace Networks makes a device which does intelligent routing of messages like this. It can do things likecompute the distance from some point to decide if it should forward a message allowing you to ask a question like: “I want to know about anything happening 30 miles from Chicago.” Very cool.
Brokers Replaced Broadcast

Instead of implementing true publish / subscribe over broadcast we ended up collectively implementing publish / subscribe over hub and spoke and created the notion of the broker. In the broker model we abstract the idea of publish / subscribe with a software component. I publish something once to the broker and it distributes it to all parties as if I had broadcast it. The broker uses hub and spoke and sends the message to each interested party. It removes a lot of the work to implement scalable reliable powerful flexible communications . It drastically simplifies integration and writing enterprise applications. I send the message once like in the broadcast model and the broker takes the load of copying it to all the interested parties and all the security and reliability issues. It takes the problem of keeping tract of who is interested in every message and manages the reliability of the message delivery to every interested party.
Conceptually then the broker is identical to publish/subscribe over broadcast but it does have the dependency on the broker and the problems we talked about earlier. Modern message brokers are efficient and deliver messages in milliseconds. Modern message brokers implement security robustly, are very reliable and can do a lot more than just distribute messages. Also, since the Internet is not “Broadcast enabled” (which is another whole story) and many corporations don’t support broadcast across their entire network the message broker became the only way to implement publish/subscribe scalably in Enterprises.
After publish/subscribe and event driven messaging came a flood of cool stuff (SOA too)
The messaging explosion of the late 80s and 90s spurred an innovation tsunami. Most enterprises followed similar paths after adopting publish/subscribe and SOA they found the following tools very useful to leverage event driven computing. These became the standard SOA tools.
Calculation Engines / Activity Monitoring
The very first thing people wanted after their data was on the “bus” was the ability to do computations on the data in realtime. Maybe I want an average of something rather than the instantaneous value? Maybe I want a computation of a combination of many related things, for instance calculating the sum of all the things bought, the average of all the stocks in the S&P. I might want to be notified when an order >$10,000 was made. This can also be used to calculate information like the load on computers which can be used to decide when to allocate more instances of a service. This activity monitoring and calculation service could be used at the operational as well as the application level.
Data Integration
Getting data on the “bus” meant having adapters and connectors to make it easy to get all your enterprise applications on the “bus.” I might like to draw a real-time graph of the history of that data. So, people wanted to integrate databases and all kinds of existing applications and protocols into the bus and make them compatible with the event driven messaging architecture. This became known as “Data Services and adapter and connection frameworks” This also was consistent with the growing belief that applications should be broken into tiers with data services separared from business and presentation levels.
Mediation
The publish/subscribe paradigm made integration easy. Part of how we did that was to build some intelligence into the routing and transaltion so that whatever information was on the bus could be combined with other data easily or broken up into pieces as all the other applications might like. Somebody figured out the common ways people wanted to combine and bifurcate message flows. This became known as EAI (Enterprise application Integration) and these message mediation patterns became standardized in Enterprise integration Patterns. This is a super powerful way to combine services and data to produce new data.
Complex Event Processing
The next thing people wanted to do was to look for patterns in the messages and do things based on those patterns. Maybe I want to look for a user looking at product X, then product Y and suggest they look at product Z automatically? Maybe I want to make an offer to them based on their activity to incentivize them to buy? Maybe I want to discover a certain behavior that is indicative of a security breach? Complex event processing enabled me to detect complex patterns in activity in the enterprise and automate it. Very powerful stuff. In today’s bigdata world this is all still very relevant.
Mashups
Once I had lots of information “on the bus” it was useful to have a tool that let me combine the information in visual ways easily. This led to the mashup craze.
Conclusion of Platform 2.0 / Distributed Era
In summary here are the traditional components of an event driven messaging architecture

Today Oracle, IBM, TIBCO, Software AG, WSO2 provide full suites of this Platform 2.0 event driven messaging technology.
Platform 3.0 The New Event Driven Architecture
I have written extensively about Platform 3.0 and the shift to a new development technology base. Here is a blog you might consider reading if you want to learn more:
Enterprise Application Platform 3.0 is a Social, Mobile, API Centric, Bigdata, Open Source, Cloud Native Multi-tenant Internet of Things IOT Platform
Platform 3.0 reinvigorates pubsub as social, mobile, IoT and the world are moving to more and more being done the instant it is possible and events to tell everyone interested about it. The pubsub philosophy is reemerging with Platform 3.0. Here is a graphical presentation of the difference between 2.0 Event Driven Components and Platform 3.0 Event Driven Components.


The IoT (Internet of Things) and Pubsub
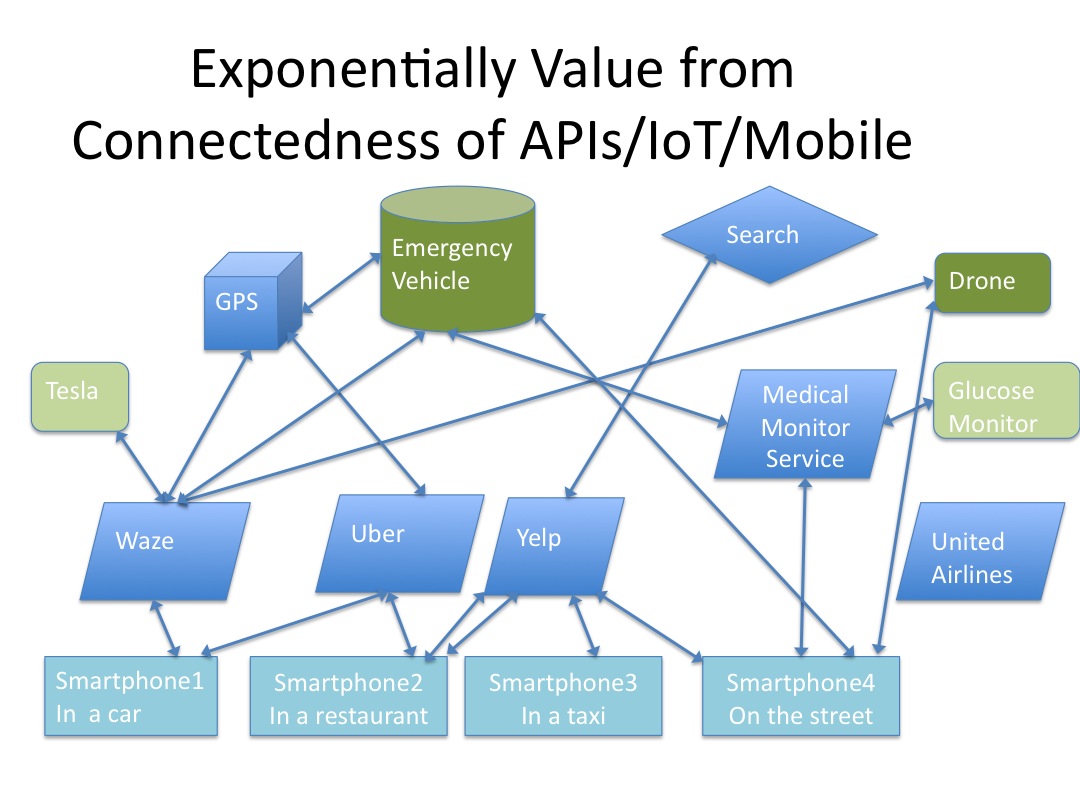
Things like Uber and Tesla two of my favorite examples prove that having devices connected has tremendous value. Uber is valued at $17 billion and it is an app that depends on IOT smartphones being ubiquitous. TESLA has changed the way cars are maintained. My car wakes up in the middle of the night every few weeks and automatically downloads a new version of itself. Last time it did this it upgraded my suspension system, my navigation system, the efficiency of my car and gave me a better way to handle driving on hills. Not bad.
In the diagram above imagine I am connected to a glucose sensor. When my body signs point to needing insulin I can be notified on my cell phone. If I am older and my family might be worried if I will do the right thing they could be informed as well and give me a call to make sure I do what I need to do. If the situation gets worse the sensor could talk to other devices around me and notify an emergency service. The emergency service might automatically know who I am and where I am (like Uber) and find me quickly. The emergency service using Waze and information about traffic on routes by IoTs all over the road system will tell me the fastest way to get to the patient. In the meantime my vital signs are being sent to the system and ultimately this data can be used by researchers to figure out how to better prevent problems in the future. IoT for health is more than about counting steps. Numerous devices are being built to measure all kinds of things in the human body and ultimately this could be immensely useful for statisticians who can figure out what affects what and what leads to what and what doesn’t lead to what.
Things talk to things directly
Imagine as you walk around you have devices on you physically or around you that are all connected and can talk to each other as well as to the internet. I admit there is a certain amount of worry how all this will work but putting aside our concerns for the moment let’s consider what the advantages this entails. My next blog will get into technical considerations to making this work well.
If you read this entire blog you will remember the “demo” I talked about we did at TIBCO many years ago. This demonstrated the power of publish/subscribe over centralized systems. If every device has to have the ability to communicate long distances, have the full capability to do everything it needs then each device becomes bigger, heavier, more expensive, breaks more often, runs out of power sooner. It would be better if each device could leverage the devices around it to get the job done or that it only needed to do a small part of a larger problem.
With pubsub I discover devices are near me and they can publish things to me and I can publish things to them. They may not be interested and I may not be interested but if we are interested we can help each other and deliver more value to the user.
An Example: I can save a lot of power if I don’t have to broadcast information over long distances. It would be awfully nice if the other devices near me were able to forward the information farther on so I don’t have to use as much battery power. In the mesh pubsub models being considered for some IoT protocols when one device publishes something another device near it can automatically forward the message closer to where it needs to go. This powerful technology is similar to the Internet TCP/IP protocol routing which gives the internet the reliability and robustness that has proven itself.
If things can talk to things directly without having to go to a central hub you remove a serious latency and a serious failure point. You also make it easier to build devices that don’t have to be “all-complete” within themselves. Devices can leverage other devices directly reducing the cost and increasing the ubiquitousness of everything.
As a result you get:
1. Higher efficiency
2. Smaller devices that use less power
3. More reliability and robustness
4. Network Effect of Devices
5. More devices, more adoption
(I don’t want to suggest that there is not a value in having a central server that knows and can interact with everything as well. All I am suggesting here is that having the ability of the devices to communicate locally and operate more autonomously leveraging each other will result in better user experience and higher reliablity.)
As a result almost all the new protocols and messaging architectures being promoted for “Internet of Things” are publish/subscribe. This is the power of publish/subscribe being leveraged again. It’s exciting to think of this entire new domain of hardware being built for the home or office on a true publish/subscribe paradigm. Some of the protocols actually look like the original publish/subscribe we did on trading floors. MQTT implements a publish/subscribe broker. Zigbee, CoAp all implement publish/subscribe semantics. CoAp already has a mesh network standard. These protocols will all be used in the new IoT devices we buy. Most of the devices can operate autonomously but if in the presence of a “hub” can talk to a hub and deliver the messages through the hub to a central server. Some devices can detect cellphones closeby.
Apple has patented an approach to security which gives you the ability when you are located in close proximity to your devices, i.e for instance in your home, that you are automatically able to access them easily but if you are not at home you have to go through an additional security step to access your devices.
My next blog is going to be a lot more technical and we will get into the details of what the pubsub IoT world looks like today and what ideas I have for how it should work.

6 thoughts on “Publish / Subscribe Event Driven Architecture in the age of Cloud, Mobile, Internet of Things(IoT), Social”